Solr (prononcé comme le mot solar en anglais) est un moteur de recherche s’appuyant sur la bibliothèque de recherche Lucene, créée par la Fondation Apache et distribuée et conçue sous licence libre. Je vous présente dans cet article quelques notions de la version SolrCloud, annoncée fault tolerant and high availability.

Solr Standalone
Dans sa version standard standalone, on définit un solr_node « master » et n solr_nodes « slave ». A l’aide d’une configuration dans solrconfig.xml, on déclare le master, les slaves et la stratégie de réplication. C’est alors Solr qui prendra en charge lui-même la synchronisation.
Sur le master
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="master">
<str name="replicateAfter">optimize</str>
<str name="backupAfter">optimize</str>
<str name="confFiles">schema.xml,stopwords.txt,elevate.xml</str>
<str name="commitReserveDuration">00:00:10</str>
</lst>
<int name="maxNumberOfBackups">2</int>
<lst name="invariants">
<str name="maxWriteMBPerSec">16</str>
</lst>
</requestHandler>
Sur les slaves
<requestHandler name="/replication" class="solr.ReplicationHandler">
<lst name="slave">
<str name="masterUrl">http://remote_host:port/solr/core_name/replication</str>
<str name="pollInterval">00:00:20</str>
<str name="compression">internal</str>
<str name="httpConnTimeout">5000</str>
<str name="httpReadTimeout">10000</str>
<str name="httpBasicAuthUser">username</str>
<str name="httpBasicAuthPassword">password</str>
</lst>
</requestHandler>
Plus de détails ici : https://lucene.apache.org/solr/guide/6_6/index-replication.html#IndexReplication-SettingUpaRepeaterwiththeReplicationHandler
Avantages / Inconvénients
- Solution native simple à mettre en place
- Les slaves se synchronisent eux-mêmes en réplicant le master.
- Avec les écritures sur le master et un load-balancer sur les slaves, on obtient une haute-disponibilité en lecture tant qu’il reste au-moins un slave en fonctionnement.
- En revanche, pas de haute-dispo pour l’écriture.
- Si un slave down est remis en service, il sera en retard par rapport au master et aux autres slaves. Il faudra alors le mettre à jour manuellement.
SolrCloud
Avec SolrCloud, on change de stratégie pour viser la haute-dispo en lecture et en écriture. SolrCloud est disponible nativement dans une installation standard Solr. Un nouveau composant, Zookeeper, entre en jeu. Nous en parlerons plus en détails dans un autre article.
Quelques concepts à définir
- cluster : c’est le groupe de serveurs (nodes) sur lequel tourne le service SolrCloud
- node : un node est un serveur qui héberge le service Solr. Un groupe de nodes composent un cluster.
- collection : elle représente un index logique dans son intégralité, fourni par le cluster SolrCloud
- shard : c’est une subdivision de la collection
- replica : c’est un index physique détenu par un node du cluster
Exemple 1 : SolrCloud avec 3 shards

- 1 cluster de 3 nodes
- 1 collection
- 3 shards (on découpe l’index en 3 parties)
- 2 replicas (= 2 cores par node)
Dans cette configuration, l’index (la collection) découpé en 3 parties (les shards) sera répliqué 1 fois (2 replicas). En conséquence, on obtient la répartition ci-dessous :
- solr_node_1
- shard1_replica1
- shard3_replica2
- solr_node_2
- shard2_replica2
- shard3_replica1
- solr_node_3
- shard1_replica2
- shard2_replica1
Pour finir d’illustrer la mécanique de répartition de SolrCloud, si on déploie une telle configuration sur un seul solr_node, il détiendra alors les 6 replicas dans 6 cores.
Avantages / Inconvénients
- Une telle configuration est haute-disponibilité en lecture et en écriture. Si on perd un solr_node, les 2 autres possèdent encore la totalité de l’index (shards 1 2 3).
- Elle assure aussi une répartition de charge car chaque solr_node a la responsabilité de seulement 1/3 de l’index, en lecture (requêtes) et en écriture (indexation).
- Il n’y a plus ni master ni slave. Tous les solr_nodes ont le même rôle et c’est Zookeeper qui se charge de gérer le cluster en fonction de l’état des solr_nodes (leader, active, down, recovering…).
- Complexité de mise en œuvre et de compréhension
- Nécessite au-moins 3 nodes
Exemple 2 : SolrCloud avec 1 shard
Avec SolrCloud, on peut mettre en place une architecture sur 2 solr_nodes, comme en mode standalone, mais avec les bénéfices de la haute-dispo en écriture.
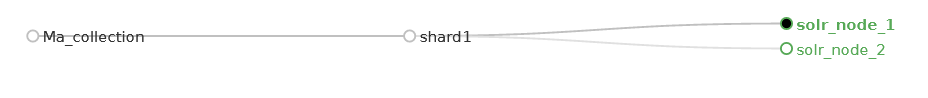
- 1 cluster de 2 nodes
- 1 collection
- 1 shard (l’index n’est pas découpé)
- 2 replicas (= 1 core par node)
Dans cette configuration, on obtient la répartition ci-dessous :
- solr_node_1
- shard1_replica1
- solr_node_2
- shard1_replica2
Avantages / Inconvénients
- Haute-disponibilité en lecture et en écriture. Si on perd un solr_node, l’autre possède encore la totalité de l’index.
- Plus « standard » et plus facile à appréhender que la version 3 nodes / 3 shards
- Il n’y a plus ni master ni slave. Tous les solr_nodes ont le même rôle et c’est Zookeeper qui se charge de gérer le cluster en fonction de l’état des solr_nodes (leader, active, down, recovering…).
- On peut sécuriser d’avantage cette installation en ajoutant des nodes.
- Pas de répartition de la charge (un seul leader). L’unique core leader doit gérer la totalité de l’index (requête + indexation).
Conclusion
SolrCloud offre un niveau de service supérieur à un Solr standalone master/slave. Si votre application en dépend fortement, SolrCloud est clairement à privilégier. De plus, si la version 3 nodes / 3 shards vous paraît complexe à mettre en œuvre, vous pouvez vous reposer sur la version avec 1 seul shard, plus simple. Vous pouvez tester SolrCloud facilement avec les images Docker officielles : https://github.com/docker-solr. Je vous parlerai de Zookeeper dans un futur article.
Sources
https://github.com/docker-solr
https://stackoverflow.com/a/31773632/243996
https://lucene.apache.org/solr/guide/8_8/
https://lucene.apache.org/solr/guide/8_8/solrcloud.html
Bonjour Franck,
Très intéressant ! Pour bien comprendre : en mode SolR Cloud 1 shard (donc avec 2 nodes), cela nécessite 2 serveurs ou 3 ? La question de fond : les nodes se parlent entre eux ou bien doivent être pilotés par un 3ème serveur ?
Merci !
Antoine